Елена Малинина, №10
25.12.2025

| ВЕСТНИК НАУФОР №10/2025 |
|---|

Директор центра экономического анализа, Группа «Интерфакс»
Молекулы разума
Применение ИИ на фондовом рынке - реальность. RAG-модели создают чат-ботов, алгоритмы ML выстраивают точные и гладкие безрисковые кривые доходности, а автоматизация разбора и анализа отчетности по МСФО проходит с применением компьютерного зрения и NLP.
Цифровая трансформация финансовой отрасли переходит от этапа автоматизации рутинных операций к глубокой интеллектуализации процессов. Современные модели искусственного интеллекта становятся не просто инструментами, а полноправными помощниками аналитиков, риск-менеджеров и управленцев. Практический опыт внедрения новых умных технологий в проекте RUDATA Группы «Интерфакс» демонстрирует, как технологии машинного обучения (machine lerning, ML), генеративного ИИ и компьютерного зрения решают сложнейшие задачи финансового рынка, такие как построение безрисковых кривых дисконтирования, анализ консолидированной отчетности и создание интеллектуальных ботов поддержки.
Проект RUDATA занимается сбором и анализом данных, необходимых финансовому рынку для подготовки отчетности, проведения оценок рисков и ценных бумаг, анализа инвестиционной деятельности. Кроме данных, RUDATA оцифровывает регуляторные модели оценки финансовой устойчивости и стресс-тестирования для банков, страховых организаций и негосударственных пенсионных фондов, а также формирует собственные математические модели, базирующиеся на классической оптимизации, линейном и выпуклом программировании, потоковых задачах и машинном обучении. В частности, исследовательская группа RUDATA создает свои оценки справедливой стоимости, value-at-risk модели.
В своей повседневной деятельности мы сталкиваемся как с задачами подбора математического аппарата и его освоения, анализа нормативно-правовых актов и иных регуляторных документов Банка России, так и с необходимостью разбора основных отчетных форм и проверки полноты и корректности полученных данных. Для решения такого характера задач с 2023 года мы используем различные модели искусственного интеллекта.
Генеративный ИИ для аналитики
Начнем с простого примера - использование генеративного ИИ для решения рутинных задач. Такой подход позволяет высвободить время аналитиков для более сложной и творческой работы. Рассмотрим несколько сценариев.
1. Подбор аналитических и научных материалов. Возможности генеративных ИИ, помимо рассуждений и генерации контента, включают умный поиск в интернете и базах данных. Мы пользуемся ими для подбора научных публикаций, задавая нейросетям, например, такие промпты: «Подбери 20 научных публикаций на тему «рыночная ликвидность акций». Отдавай предпочтение наиболее актуальным статьям. Публикации ранжируй по степени достоверности источника. Укажи, какой подход к анализу достоверности используешь».
2. Анализ текстов и нормативных документов. ИИ способен за минуты проанализировать сотни страниц: составить обзоры научных статей, вычленить ключевые термины и определения из диссертаций, а из нормативных актов (например, решений Банка России) - извлечь сроки вступления в силу, целевую аудиторию и структурированные таблицы для классификации активов.
3. Обучение и объяснение сложных тем. Поскольку мы часто сталкиваемся с трудными подходами из математики, машинного обучения, экономики, то в таких случаях стараемся также понять физику процесса. Для этого используем промпты вида: «Объясни мне, как ученику 9 класса, что такое рыночная ликвидность. Используй аналогии и примеры из жизни». Тогда генеративный ИИ выступает в роли персонального научного консультанта, способного донести суть сложных экономических понятий или моделей простым языком.
4. Генерация и обработка данных. Генеративный ИИ используется нами для преобразования данных из одного формата в другой (например, разбор простого PDF-файла в CSV), создания синтетических датасетов для тестирования моделей и даже генерации типовых вопросов от клиентов для отладки продуктов. В частности, для разбора файла PDF со статистикой штрафов, сформированного по данным сайта Банка России, использовался промпт: «Напиши python-код для формирования CSV-файла, в котором должны быть следующие столбцы: дата нарушения, размер штрафа, тип наказания = штраф или предупреждение, лицо, к которому применяется штраф». Он позволил подготовить код на языке python, который производил разбор документа. Поскольку модели ИИ с модулем рассуждения также показывают, как они «обдумывали» данные, то видно, какие сложности в представленном файле встречаются и как ИИ предлагает их обойти. Далее нашим аналитикам данных осталось отладить код и обработать сложные ветки алгоритма, не учтенные ИИ.
Согласно своей природе, генеративный ИИ не всегда надежен в выполнении сложных математических расчетов, поэтому его основная роль - ассистирующая, а не замена специализированных вычислительных систем и аналитиков. Однако, обобщение материалов, краткий пересказ, выделение ключевых элементов, сравнение текстов - тот функционал, который хорошо выполняет генеративный ИИ.
Интеллектуальный разбор МСФО
Задача агрегации и анализа данных из финансовой отчетности остается одной из самых трудоемких. Поскольку в основе нескольких наших моделей лежат показатели консолидированной отчетности, раскрывающейся эмитентами согласно стандартам МСФО, появилась задача автоматизированного разбора форм для оперативной актуализации информации.
Как правило, отчеты состоят из 10-100 страниц, из которых только 3-5 посвященных непосредственно финансовым показателям. Эти страницы могут быть представлена как в виде текстового PDF (машиночитаемый, преобразованный из Word), так и в виде отсканированных листов бумажных документов с подписями и печатями. Причем число показателей и данные, которые к ним относятся, отличаются (иногда значительно) для компаний из различных отраслей. Поэтому в RUDATA мы разработали унифицированную форму, в которую преобразовываем данные трех типовых отчетных форм - баланса, отчета о движении денежных средств и отчета о прибылях и убытках (финансовый результат). Для четкого разнесения по агрегированным показателям нашей формы необходим анализ примечаний к отчетности. А поскольку нам важны качественные данные, по завершении формирования наших таблиц необходимо провести тестирование полноты, адекватности и связанности форм.

Таким образом, задача по разбору отчетности сводится к трем шагам, а именно:
1. Разбор основных таблиц.
2. Разнесение данных по агрегированным показателям и ручная корректировка на основе примечаний для тех позиций, которые не были разнесены автоматизировано.
3. Проведение автоматизированных проверок:
a. сверка показателей внутри одной формы (например, равенство частных показателей в сумме общим) и между разными формами отчетности (например, выполнение Х(t) = X(t-1) + разница, где разница анализируется по движению денежных средств);
b. выполнение Z-теста (попадание в среднее и доверительный интервал к нему) для выявления аномалий в ключевых индикаторах, рассчитанных по сформированным формам.
Для автоматизации этого процесса в продуктах Группы «Интерфакс» применяется гибридное решение, созданное нашими дата-саентистами на языке Python:
По результатам работы созданная система формирует Excel-файл с агрегированными счетами и результатами проверки. Качество распознавания текстовых PDF-страниц достигает 99-100%, в то время как для сканов оно сильно зависит от качества исходного изображения (угол поворота, цветность, контраст) и может варьироваться от 20-30% до 90%. Тем не менее, даже частичная автоматизация этого процесса приносит значительный эффект.
Однако мы видим и точки роста: снижение времени работы человека для реализации ручных корректировок, а также совершенствование проверок, в частности сравнение частных индикаторов с отраслевыми.
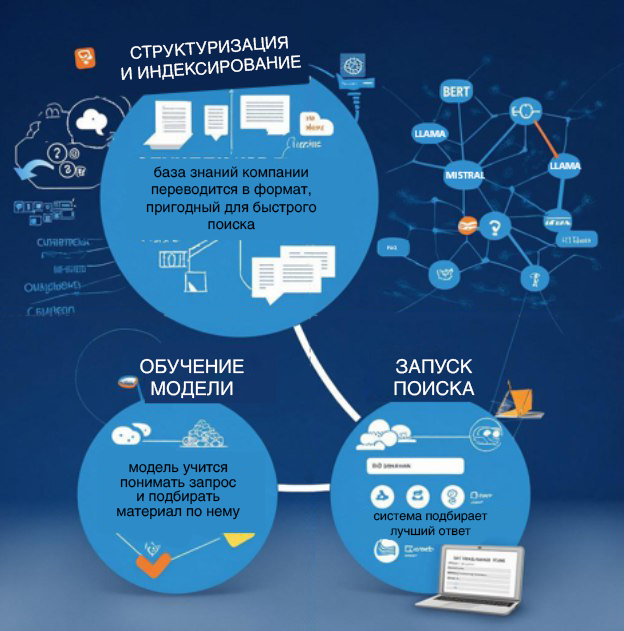
«Библиотекарь» для базы знаний
Одной из самых практичных и быстро внедряемых технологий является RAG (Retrieval-Augmented Generation) или генерация с поддержкой извлечения. Ее суть заключается в создании интеллектуального интерфейса для работы с обширными внутренними базами знаний, документации и кода. В 2025 году в RUDATA мы активно начали использовать этот подход:
Наша практика показала, что внедрение RAG-системы проходит в три ключевых этапа:
1. Структуризация и индексирование. Вся база знаний компании - описания методологий, часто задаваемые вопросы и документация к API - структурируется и переводится в формат, пригодный для быстрого поиска. Этот этап занимает 60-70% времени, поскольку требует очень качественной очистки, обработки и уточнения данных.
2. Обучение модели. Специальная модель (например, на основе BERT) или готовая генеративная модель с открытым кодом (например, llama или mistral) обучается понимать смысл запросов пользователей и сопоставлять их с релевантными фрагментами из проиндексированной базы.
3. Запуск системы поиска. Когда аналитик вводит запрос, например, «как получить безрисковую кривую в долларах», система не просто ищет совпадения по ключевым словам. Она семантически находит наиболее подходящие фрагменты кода или документации, отбирает лучший и представляет результат в удобном виде: ссылкой на метод API с указанием параметров, сопровождая пояснением и примерами кода.
По сути, RAG выступает в роли высококвалифицированного библиотекаря, который не только находит нужную «книгу» (знание) в гигантском архиве, но и сразу открывает ее на нужной странице, предлагая краткую выжимку. Это значительно ускоряет онбординг новых сотрудников, снижает нагрузку на наших экспертов и повышает согласованность используемых подходов в рамках всего нашего исследовательского центра.
Безрисковые кривые от ML
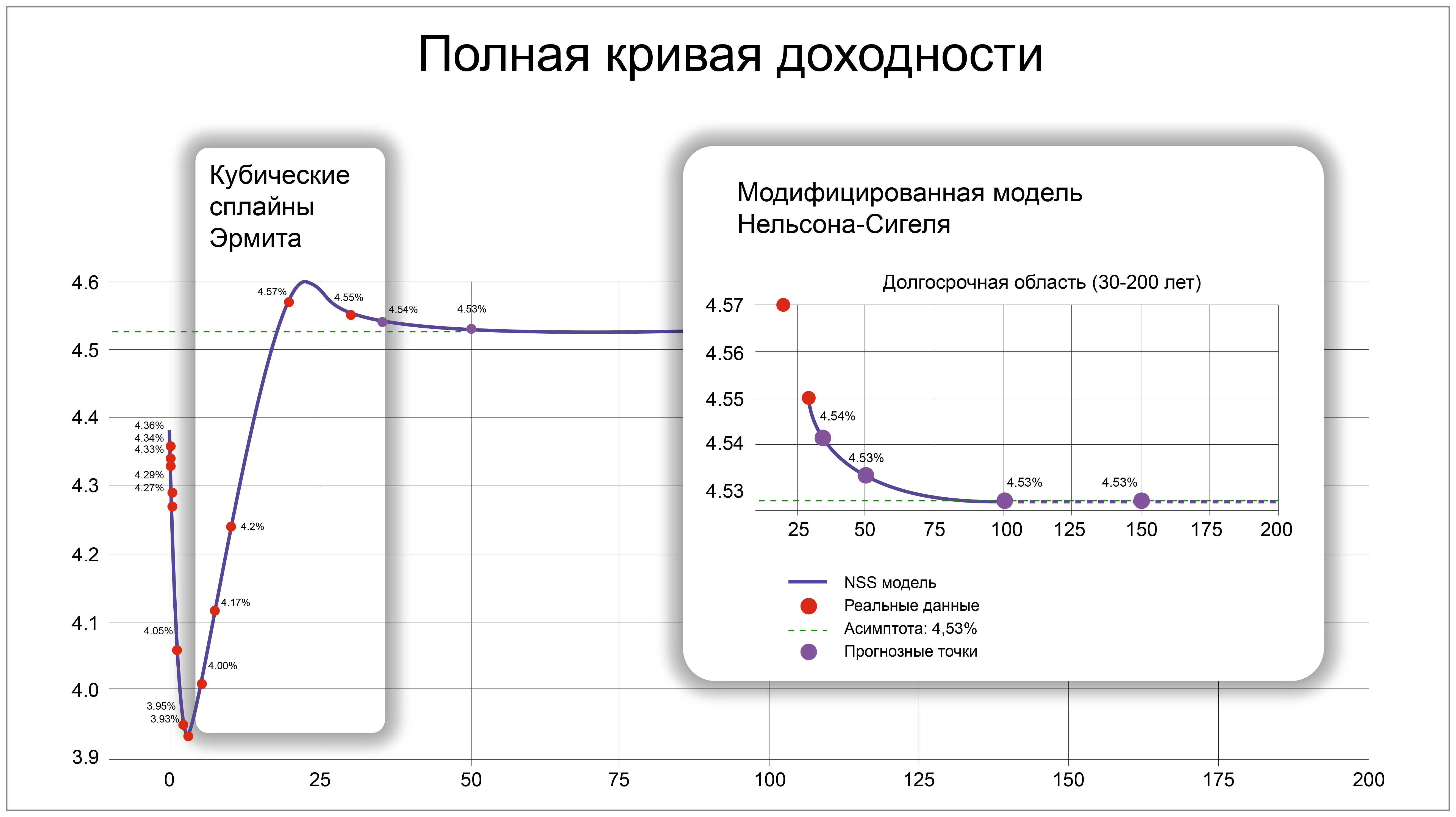
Построение безрисковой кривой доходности - фундаментальная задача для оценки стоимости активов и обязательств, управления рисками и проведения макроэкономического анализа. Такого характера кривые используются как консервативные ставки дисконтирования, а традиционными методами их построения являются кубические сплайны или модель Нельсона-Сигеля. Рассчитанные точки кривой раскрываются регуляторами или казначействами разных стран на их интернет-страницах.
Однако для дисконтирования денежного потока по облигации или по договору страхования необходимо знать значение кривой в каждой временной точке. Для этого могут быть использованы линейные или полиномиальные интерполяционные модели, которые способны серьезно искажать качество результата, а также сильно менять вид кривой от точки к точке.
Практика «Интерфакса» показывает, как машинное обучение позволяет преодолеть эти ограничения. Для решения задачи расчета безрисковой кривой в долларах применяется двухэтапный подход:
1. Использование модифицированных кубических сплайнов Эрмита для построения кривой внутри известного диапазона. В отличие от стандартных сплайнов, эта модель учитывает не только значения доходности в ключевых точках (дюрациях), но и их производные (тангенсы угла наклона). Это позволяет контролировать форму кривой и гарантирует ее гладкость. Для борьбы с шумами данные дополнительно сглаживаются статистическими фильтрами (например, Савицкого-Голея), что устраняет пилообразные эффекты.
2. Применение модифицированной модели Нельсона-Сигеля-Свенссона с плавной асимптотой (NSS). Для сроков свыше 30 лет, где рыночных данных недостаточно, классические модели могут вести себя нестабильно. Модифицированная NSS-модель вводит функцию плавного перехода к долгосрочной асимптоте. До 25 лет кривая точно следует за известными данными, а после этого срока включается механизм экспоненциального затухания отклонений от асимптотического значения. Это обеспечивает финансово логичное и математически корректное поведение кривой на сверхдлинных горизонтах, что критически важно для пенсионных фондов и страховых компаний.
Точки с малыми дюрациями также рассматриваются отдельно и для них разрабатывается своя модель.
Такой гибридный подход, сочетающий классические финансовые модели с алгоритмами машинного обучения, позволяет строить гладкие, точные и финансово состоятельные кривые доходности для любых дюраций.
Опыт RUDATA Группы «Интерфакс» подтверждает, что ИИ перестал быть абстрактной технологией будущего. Сегодня это набор конкретных, проверенных на практике инструментов, которые решают критически важные задачи финансового рынка. Комбинация RAG-систем, продвинутых моделей машинного обучения для количественного анализа, генеративного ИИ для автоматизации рутины и компьютерного зрения для обработки документов создает мощный симбиоз, многократно повышающий эффективность, скорость и глубину аналитической работы. Внедрение этих технологий позволяет не только сокращать издержки, но и открывать новые возможности для анализа данных, что формирует новое качество финансовых услуг и управленческих решений.
Биография
Елена Малинина - к. э. н., директор центра экономического анализа, Группа «Интерфакс». Елена занимается экономическими исследованиями, математическим моделированием и анализом данных, а также является владельцем ИТ-продукта. Образование: МГУ им. М. В. Ломоносова (ВМК), РЭУ им. Г. В. Плеханова (бухучет, статистика).
Журнал «Вестник НАУФОР» - это ежемесячный журнал с познавательными статьями о практике работы на рынке ценных бумаг, обзорами рынка, интервью с ведущими его представителями, материалами конференций рынка ценных бумаг.
Авторами журнала являются профессиональные финансисты: брокеры, управляющие, аналитики, корпоративные юристы, риск-менеджеры, представители инфраструктуры. Зная профессию изнутри, эти люди пишут о том, что действительно является повесткой их рабочего дня. Уровень понимания и анализа конкретных проблем задан принадлежностью авторов к индустрии финансов.
Читателями журнала «Вестника НАУФОР» являются представители госорганов, Банка России, руководители и специалисты финансовых компаний - профучастников рынка ценных бумаг и управляющих компаний, инвестиционные консультанты.
По вопросам приобретения печатной версии издания связываться с Мироновой Татьяной - mironova@naufor.ru